20 korisnih primjera naredbi egrep u Linuxu
Ukratko: u ovom ćemo vodiču raspravljati o nekim praktičnim primjerima naredbe egrep. Nakon što slijede ovaj vodič, korisnici će moći učinkovitije pretraživati tekst u Linuxu.
Jeste li ikada bili frustrirani jer ne možete pronaći potrebne informacije u zapisima? Izdvajanje potrebnih informacija iz velikog skupa podataka složen je i dugotrajan zadatak.
Stvari postaju zaista izazovne ako operativni sustav ne nudi prave alate i tu dolazi Linux da vas spasi. Linux nudi razne alate za filtriranje teksta kao što su awk, sed, cut, itd.
Međutim, egrep je jedan od najmoćnijih i najčešće korištenih uslužnih programa za obradu teksta u Linuxu, a mi ćemo raspravljati o nekim primjerima naredbe egrep.
Naredba egrep u Linuxu prepoznaje se po obitelji naredbi grep, koja se koristi za pretraživanje i podudaranje s određenim uzorkom u datotekama. Radi slično kao grep -E (grep Extended regex), ali uglavnom pretražuje određenu datoteku ili čak redak do retka ili ispisuje redak u datoteci.
Sintaksa naredbe egrep je sljedeća:
egrep [OPTIONS] PATTERNS [FILES]
Stvorimo oglednu tekstualnu datoteku sa sljedećim sadržajem kao primjer:
cat sample.txt

Ovdje možemo vidjeti da je tekstualna datoteka spremna. Sada raspravimo nekoliko uobičajenih primjera koji se mogu koristiti svakodnevno.
1. Kako pronaći uzorak u jednoj datoteci
Počnimo s jednostavnim primjerom podudaranja uzorka, gdje možemo upotrijebiti naredbu ispod za traženje niza professional u datoteci sample.txt:
egrep professionals sample.txt

Ovdje možemo vidjeti da naredba ispisuje redak koji sadrži navedeni uzorak.
2. Kako označiti podudarne uzorke u datoteci
Ispis možemo učiniti informativnijim isticanjem odgovarajućeg uzorka. Da bismo to postigli, možemo koristiti opciju --color naredbe egrep. Na primjer, donja naredba označit će tekst profesionalci crvenom bojom:
egrep --color=auto professionals sample.txt

Ovdje možemo vidjeti da je isti izlaz informativniji u usporedbi s prethodnim. Također, lako možemo prepoznati da se riječ profesionalci ponavlja dva puta.
Na većini Linux sustava gornja postavka omogućena je prema zadanim postavkama koristeći sljedeći alias:
alias egrep='egrep –color=auto'
3. Kako pronaći uzorak u više datoteka
Naredba egrep prihvaća više datoteka kao argument, što nam omogućuje traženje određenog uzorka u više datoteka. Shvatimo ovo na primjeru.
Najprije izradite kopiju datoteke sample.txt:
cp sample.txt sample-copy.txt
Sada pretražite uzorak professionals u obje datoteke:
egrep professionals sample.txt sample-copy.txt

U gornjem primjeru, možemo vidjeti naziv datoteke u izlazu, koji predstavlja odgovarajući redak iz te datoteke.
4. Kako brojati odgovarajuće retke u datoteci
Ponekad samo trebamo saznati postoji li uzorak u datoteci ili ne. Ako da, u koliko je redaka prisutan? U takvim slučajevima možemo koristiti opciju -c naredbe.
Na primjer, donja naredba prikazat će 1 kao izlaz jer je riječ professionals prisutna u samo jednom retku.
egrep -c professionals sample.txt
1
5. Kako ispisati samo odgovarajuće retke u datoteci
U prethodnom primjeru vidjeli smo da opcija -c ne broji broj pojavljivanja uzorka. Na primjer, riječ profesionalci pojavljuje se dva puta u istom retku, ali opcija -c tretira je kao samo jedno podudaranje.
U takvim slučajevima možemo upotrijebiti opciju -o naredbe za ispis samo odgovarajućeg uzorka. Na primjer, donja naredba prikazat će riječ profesionalci u dva odvojena retka:
egrep -o professionals sample.txt
Sada prebrojimo retke pomoću naredbe wc:
egrep -o professionals sample.txt | wc -l

U gornjem primjeru upotrijebili smo kombinaciju naredbi egrep i wc za brojanje broja pojavljivanja određenog uzorka.
6. Kako pronaći obrazac zanemarivanjem velikih i malih slova
Prema zadanim postavkama, egrep izvodi podudaranje uzoraka na način koji razlikuje velika i mala slova. To znači riječi - mi, mi, mi i MI se tretiraju kao različite riječi. Međutim, možemo nametnuti pretraživanje koje ne razlikuje velika i mala slova pomoću opcije -i.
Na primjer, u donjoj naredbi podudaranje uzorka uspjet će za tekst mi i Mi:
egrep -i we sample.txt

7. Kako isključiti djelomično podudarne uzorke
U prethodnom primjeru vidjeli smo da naredba egrep izvodi djelomično podudaranje. Na primjer, kada smo tražili tekst mi, podudaranje uzorka je uspjelo i za druge tekstove. Kao što su web, web stranica i bili.
Da bismo prevladali ovo ograničenje, možemo koristiti opciju -w koja nameće podudaranje cijele riječi.
egrep -w we sample.txt

8. Kako obrnuti podudaranje uzorka u datoteci
Do sada smo koristili naredbu egrep za ispis redaka u kojima je prisutan zadani uzorak. Međutim, ponekad želimo operaciju izvesti na suprotan način.
Na primjer, možemo htjeti ispisati retke u kojima zadani uzorak nije prisutan. To možemo postići uz pomoć -v opcije:
egrep -v we sample.txt

Ovdje možemo vidjeti da naredba ispisuje sav redak koji ne sadrži tekst we.
9. Kako pronaći broj retka uzorka
Možemo upotrijebiti opciju -n naredbe da omogućimo numeriranje redaka, koji prikazuje broj retka u izlazu kada usklađivanje uzorka uspije. Ovaj jednostavan trik čini rezultat smislenijim.
egrep -n professionals sample.txt

U gornjem izlazu možemo vidjeti da je riječ profesionalci prisutna u 5. retku.
10. Kako izvršiti usklađivanje uzorka u tihom načinu rada
U tihom načinu rada, naredba egrep ne ispisuje odgovarajući uzorak. Dakle, moramo upotrijebiti povratnu vrijednost naredbe kako bismo utvrdili je li podudaranje uzoraka uspjelo ili nije.
Možemo upotrijebiti opciju -q naredbe da omogućimo tihi način rada, što je zgodno prilikom pisanja skripti ljuske.
egrep -q professionals sample.txt
egrep -q non-existing-pattern sample.txt
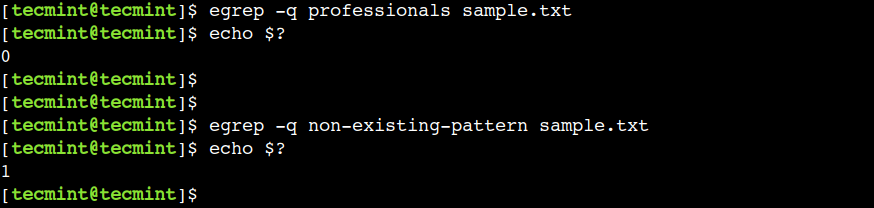
U ovom primjeru, povratna vrijednost nula označava prisutnost uzorka, dok vrijednost različita od nule označava odsutnost uzorka.
11. Kako prikazati linije prije podudaranja uzorka
Ponekad ima smisla prikazati nekoliko linija oko odgovarajućeg uzorka. Za takve scenarije možemo koristiti opciju -B naredbe, koja prikazuje N redaka prije odgovarajućeg uzorka.
Na primjer, donja naredba ispisat će redak za koji je uspjelo podudaranje uzorka, kao i 2 retka prije njega.
egrep -B 2 -n professionals sample.txt

U ovom smo primjeru upotrijebili opciju -n za prikaz brojeva redaka.
12. Kako prikazati linije nakon podudaranja uzorka
Na sličan način možemo koristiti opciju -A naredbe za prikaz redaka nakon podudaranja uzorka. Na primjer, donja naredba ispisat će redak za koji je uspjelo podudaranje uzorka, kao i sljedeća 2 retka.
egrep -A 2 -n professionals sample.txt

13. Kako prikazati linije oko podudaranja uzorka
Osim toga, naredba egrep podržava opciju -C koja kombinira funkcionalnost opcija -A i -B, koji prikazuje retke prije i poslije podudarnog uzorka.
egrep -C 2 -n professionals sample.txt

14. Kako rekurzivno pronaći uzorak u više datoteka
Kao što je prethodno objašnjeno, možemo izvršiti podudaranje uzoraka na više datoteka. Međutim, situacija postaje škakljiva kada su datoteke prisutne u više poddirektorija i sve ih prosljeđujemo kao argumente naredbe.
U takvim slučajevima možemo izvršiti podudaranje uzorka na rekurzivan način pomoću opcije -r kao što je prikazano u sljedećem primjeru.
Najprije stvorite 2 poddirektorija i kopirajte datoteku sample.txt u njih:
mkdir -p dir1/dir2
cp sample.txt dir1/
cp sample.txt dir1/dir2/
Izvedimo sada operaciju pretraživanja na rekurzivan način:
egrep -r professionals dir1

U gornjem primjeru možemo vidjeti da je podudaranje uzorka uspjelo za datoteke dir1/dir2/sample.txt i dir1/sample.txt.
15. Kako spojiti jedan znak pomoću regularnih izraza
Možemo upotrijebiti znak (.) za podudaranje bilo kojeg pojedinačnog znaka osim za kraj retka. Na primjer, regularni izraz ispod odgovara tekstu har, hat i ima:
egrep "ha." sample.txt

16. Kako spojiti nula ili više pojavljivanja znaka
Možemo koristiti zvjezdicu (*) za podudaranje s nula ili više pojavljivanja prethodnog znaka. Na primjer, donji regularni izraz odgovara tekstu koji sadrži niz we iza kojeg slijedi nula ili više pojavljivanja znaka b.
egrep "web*" sample.txt

17. Kako spojiti jedno ili više pojavljivanja prethodnog znaka
Možemo koristiti plus (+) za podudaranje jednog ili više pojavljivanja prethodnog znaka. Na primjer, donji regularni izraz odgovara tekstu koji sadrži niz we iza kojeg slijedi barem jedno pojavljivanje znaka b.
egrep "web+" sample.txt

Ovdje možemo vidjeti da podudaranje uzoraka ne uspijeva za riječi - mi i bili, zbog nepostojanja znaka b.
18. Kako uskladiti početak reda
Možemo koristiti umetanje (^) za predstavljanje početka retka. Na primjer, donji regularni izraz ispisuje retke koji počinju tekstom Mi:
egrep "^We" sample.txt

19. Kako spojiti kraj retka
Možemo koristiti dolar ($) za predstavljanje kraja retka. Na primjer, donji regularni izraz ispisuje retke koji završavaju tekstom e.:
egrep "e.$" sample.txt

20. Kako ukloniti prazne retke u datoteci
Možemo upotrijebiti znak za umetanje (^) odmah iza kojeg slijedi dolar ($) za predstavljanje praznog retka. Upotrijebimo ovo u regularnom izrazu za uklanjanje praznih redaka:
egrep -n -v "^$" sample.txt
![]()
U gornjem izlazu možemo vidjeti da brojevi redaka 2, 4, 6, 8 i 10 nisu prikazani jer su prazni.
Zaključak
U ovom smo članku raspravljali o nekim korisnim primjerima naredbi egrep. Ovi se primjeri mogu koristiti u svakodnevnom životu za poboljšanje produktivnosti.
Znate li za neki drugi najbolji primjer naredbe egrep u Linuxu? Recite nam svoje stavove u komentarima ispod.