Kako instalirati Hadoop Single Node Cluster (pseudonode) na CentOS 7
Hadoop je okvir otvorenog koda koji se široko koristi za rad s Bigdata. Većina projekata Bigdata/Data Analytics izgrađena je na vrhu Hadoop Eco-System. Sastoji se od dva sloja, jedan je za pohranu podataka, a drugi za obradu podataka.
Za pohranu pobrinut će se vlastiti datotečni sustav pod nazivom HDFS (Hadoop distribuirani datotečni sustav), a obrada će se preuzeti brine YARN (Još jedan pregovarač o resursima). Mapreduce je zadani mehanizam za obradu Hadoop Eco-System.
Ovaj članak opisuje postupak instaliranja instalacije Pseudonode za Hadoop, gdje će biti svi daemoni (JVM-ovi) pokretanje klastera Single Node na CentOS 7.
Ovo je uglavnom za početnike za učenje Hadoopa. U stvarnom vremenu, Hadoop bit će instaliran kao klaster s više čvorova gdje će se podaci distribuirati među poslužiteljima kao blokovi, a posao će se izvršavati na paralelan način.
Preduvjeti
- Minimalna instalacija CentOS 7 poslužitelja.
- Izdanje Java v1.8.
- Hadoop 2.x stabilno izdanje.
Na ovoj stranici
- Kako instalirati Javu na CentOS 7
- Postavite prijavu bez lozinke na CentOS 7
- Kako instalirati Hadoop Single Node u CentOS 7
- Kako konfigurirati Hadoop u CentOS 7
- Formatiranje HDFS datotečnog sustava putem NameNode
Instaliranje Jave na CentOS 7
1. Hadoop je eko-sustav koji se sastoji od Jave. Java mora biti instalirana u našem sustavu da bismo instalirali Hadoop.
yum install java-1.8.0-openjdk
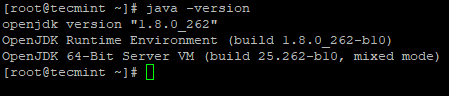
2. Zatim provjerite instaliranu verziju Jave na sustavu.
java -version
Konfigurirajte prijavu bez lozinke na CentOS 7
Moramo imati ssh konfiguriran na našem računalu, Hadoop će upravljati čvorovima pomoću SSH. Glavni čvor koristi SSH vezu za povezivanje svojih podređenih čvorova i izvođenje operacija poput pokretanja i zaustavljanja.
Moramo postaviti ssh bez lozinke tako da master može komunicirati sa podređenim uređajima koristeći ssh bez lozinke. Inače za svaku uspostavu veze potrebno je unijeti lozinku.
U ovom pojedinačnom čvoru, Master usluge (Namenode, Secondary Namenode & Resource Manager) i Slave< usluge (Datanode & Nodemanager) radit će kao zasebni JVM-ovi. Iako je jednostruki čvor, moramo imati ssh bez lozinke kako bi Master komunicirao Slave bez autentifikacije.
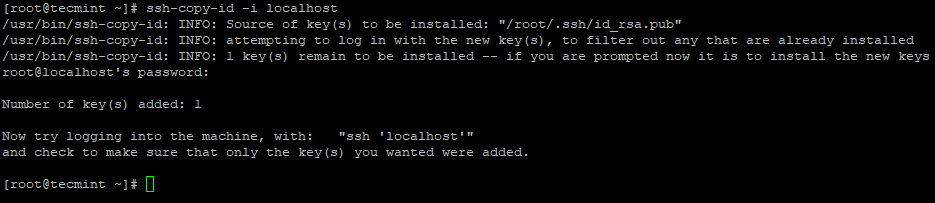
3. Postavite SSH prijavu bez lozinke pomoću sljedećih naredbi na poslužitelju.
ssh-keygen
ssh-copy-id -i localhost

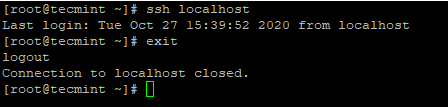
4. Nakon što ste konfigurirali SSH prijavu bez lozinke, pokušajte se ponovno prijaviti, bit ćete povezani bez lozinke.
ssh localhost
Instaliranje Hadoopa u CentOS 7
5. Idite na web mjesto Apache Hadoop i preuzmite stabilno izdanje Hadoopa pomoću sljedeće naredbe wget.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz
tar xvpzf hadoop-2.10.1.tar.gz
6. Zatim dodajte varijable okruženja Hadoop u datoteku ~/.bashrc kao što je prikazano.
HADOOP_PREFIX=/root/hadoop-2.10.1
PATH=$PATH:$HADOOP_PREFIX/bin
export PATH JAVA_HOME HADOOP_PREFIX
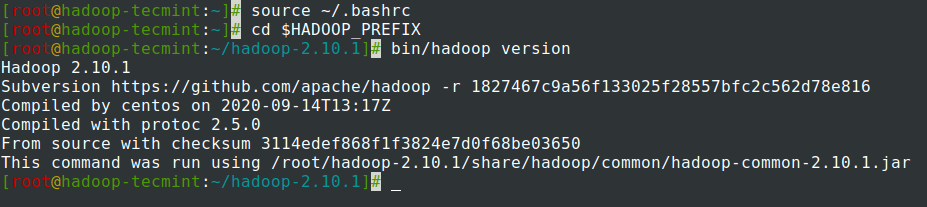
7. Nakon dodavanja varijabli okoline u ~/.bashrc datoteku, izvor datoteke i provjerite Hadoop pokretanjem sljedećih naredbi.
source ~/.bashrc
cd $HADOOP_PREFIX
bin/hadoop version
Konfiguriranje Hadoopa u CentOS 7
Moramo konfigurirati donje Hadoop konfiguracijske datoteke kako bi se uklopile u vaš stroj. U Hadoopu svaka usluga ima svoj broj priključka i vlastiti direktorij za pohranu podataka.
- Hadoop konfiguracijske datoteke – core-site.xml, hdfs-site.xml, mapred-site.xml & yarn-site.xml
8. Prvo, moramo ažurirati JAVA_HOME i Hadoop stazu u datoteci hadoop-env.sh kao što je prikazano .
cd $HADOOP_PREFIX/etc/hadoop
vi hadoop-env.sh
Unesite sljedeći redak na početku datoteke.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0/jre
export HADOOP_PREFIX=/root/hadoop-2.10.1
9. Zatim izmijenite datoteku core-site.xml.
cd $HADOOP_PREFIX/etc/hadoop
vi core-site.xml
Zalijepite sljedeće između oznaka <configuration> kao što je prikazano.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
10. Stvorite donje direktorije u tecmint korisničkom početnom direktoriju, koji će se koristiti za NN i DN pohranu.
mkdir -p /home/tecmint/hdata/
mkdir -p /home/tecmint/hdata/data
mkdir -p /home/tecmint/hdata/name
10. Zatim izmijenite datoteku hdfs-site.xml.
cd $HADOOP_PREFIX/etc/hadoop
vi hdfs-site.xml
Zalijepite sljedeće između oznaka <configuration> kao što je prikazano.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/tecmint/hdata/name</value>
</property>
<property>
<name>dfs .datanode.data.dir</name>
<value>home/tecmint/hdata/data</value>
</property>
</configuration>
11. Ponovno izmijenite datoteku mapred-site.xml.
cd $HADOOP_PREFIX/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
Zalijepite sljedeće između oznaka <configuration> kao što je prikazano.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
12. Na kraju, izmijenite datoteku yarn-site.xml.
cd $HADOOP_PREFIX/etc/hadoop
vi yarn-site.xml
Zalijepite sljedeće između oznaka <configuration> kao što je prikazano.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Formatiranje HDFS datotečnog sustava putem NameNode
13. Prije pokretanja Klustera, moramo formatirati Hadoop NN u našem lokalnom sustavu gdje je instaliran. Obično će se to učiniti u početnoj fazi prije prvog pokretanja klastera.
Formatiranje NN uzrokovat će gubitak podataka u NN metastoreu, stoga moramo biti oprezniji, ne bismo trebali formatirati NN dok klaster radi osim ako to nije namjerno potrebno.
cd $HADOOP_PREFIX
bin/hadoop namenode -format

14. Pokrenite NameNode demon i DataNode demon: (port 50070).
cd $HADOOP_PREFIX
sbin/start-dfs.sh
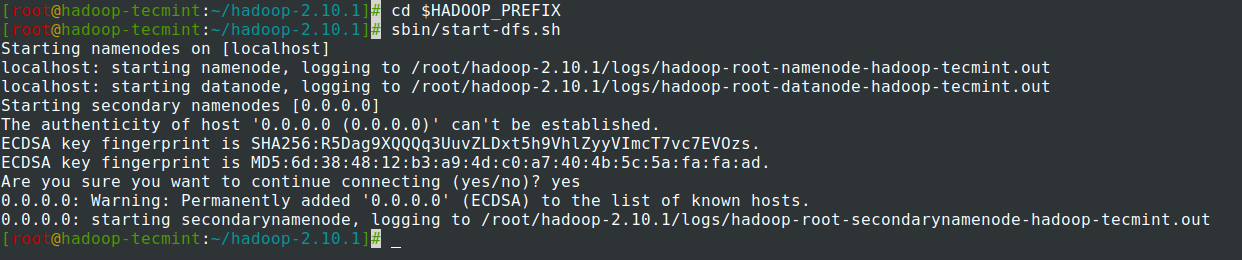
15. Pokrenite ResourceManager demon i NodeManager demon: (priključak 8088).
sbin/start-yarn.sh

16. Za zaustavljanje svih usluga.
sbin/stop-dfs.sh
sbin/stop-dfs.sh
Sažetak
Sažetak
U ovom smo članku prošli kroz postupak korak po korak za postavljanje Klustera Hadoop pseudonod (Jedan čvor). Ako imate osnovno znanje o Linuxu i slijedite ove korake, klaster će biti GORE za 40 minuta.
Ovo može biti vrlo korisno za početnike da počnu učiti i prakticirati Hadoop ili se ova vanilla verzija Hadoopa može koristiti u razvojne svrhe. Ako želimo imati klaster u stvarnom vremenu, trebamo imati najmanje 3 fizička poslužitelja ili moramo osigurati Cloud za više poslužitelja.